データの活用が教育の変革をもたらす
第57回オンラインシンポレポート・前半
活動報告|レポート

概要
超教育協会は、2021年8月4日、東北大学大学院情報科学研究科教授/東京学芸大学大学院教育学研究科教授の堀田 龍也氏を招いて、「データ駆動型の教育を目指して」と題したオンラインシンポジウムを開催した。
前半は、堀田氏が学習データを利活用で教育がどのように変革するか、データ駆動型教育の可能性と実現に向けた課題を解説。後半では超教育協会理事長の石戸 奈々子をファシリテーターに、参加者を交えての質疑応答を実施した。その前半の模様を紹介する。
>> 後半のレポートはこちら
>> シンポジウム動画も公開中!Youtube動画
■日時:2021年8月4日(水)12時~12時55分
■講演:堀田 龍也氏
東北大学大学院情報科学研究科教授/東京学芸大学大学院教育学研究科教授
■ファシリテーター:石戸 奈々子
超教育協会理事長
堀田氏は約45分の講演において、データ駆動型の教育という言葉が国の文書の中でどう使われてきたか、データ駆動型教育を進めることによる紙中心の教育の変革の可能性、デジタル教科書と教育データ利活用、学習履歴の解析からわかることについて説明した。その主な講演内容は以下のとおり。
【堀田氏】
データ駆動型の教育とはそもそも何か。政府の教育再生実行会議が2021年6月3日に出した第十二次提言「ポストコロナ期における新たな学びの在り方について」では、「データ駆動型の教育」という言葉が14箇所、記載されています。データ駆動型の教育に転換することで、例えば、学習履歴のデータをもとに一人ひとりに応じた指導が可能となるなどメリットが多くあることが書かれています。また、今後、デジタル教科書、デジタル教材などの教育コンテンツの連携が進展することを考えると、学習や指導に関連するデータを集めやすくなります。例えば、「どの教科書のどの部分で間違えた子どもには、どの教材でリカバーするとうまくいく」といったことまでデータで示されるようになると、効果的な教育に繋がることも考えられます。

▲ スライド1・教育再生実行会議の第十二次提言
第十二次提言の最後の方には、教育政策は「エビデンスベースでポリシーメイキングをしなくてはいけない」とも書かれています。一般企業では重要な経営判断は経営者の勘ではなく、売上などさまざまなデータの分析に基づいてなされ、次の手が打たれていきます。
ところが教育においては、教師の勘に頼ってしまっているところがあります。ベテラン教師の勘は貴重ですが、若手教育では勘に頼るほどの経験も少なく、さらに教育自体も様変わりをしている時代です。また、昔の勘が通用しない時代であり、ベテラン教師のクラスが学級崩壊することも珍しくありません。昔のやり方が通用しなくなったという現実の中に学校教育はあるのです。
そうした時代にあって、学習履歴をうまく集めて学習状況を把握できれば、エビデンスベースで指導ができます。そういったデータがマクロに集まれば、教育政策の妥当性の検証にも繋がるのではないかといった主旨の内容が書かれています。
学校教育の現場で、データの活用をどこからどのように進めていけばいいのか。今、小学校に入学すると保護者は学校から大量の紙を渡されて、名前、住所、生年月日、家の地図、アレルギーなどを何回も書いて提出します。
なぜ何回も書かなくてはならないかというと使う人が違うからです。こういった書類の整備や手続きについては、地域によってやり方が異なることも多く、共通化されていません。これは行政の情報化の問題とも関係します。
もし、こうした情報をデジタル化できれば、必要な情報を一度、データベースに入れておくと、そのデータを利活用できます。行政や学校が完全に情報化していない現状では、エンドユーザーである保護者が手書きしなければなりませんが、その課題を解決するには仕組みが必要です。学校が子どもや保護者に氏名と番号を付与して、アレルギーや習い事など必要な情報を入力してもらうような仕組みができれば便利に使えます。その他にも、メールマガジンで学校からの通知が届く仕組みなどがあると便利でしょう。
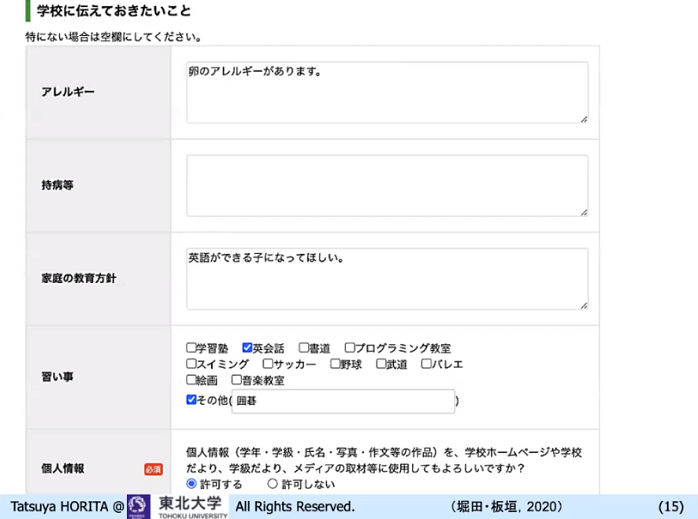
▲ スライド2・子どもの情報が一元管理できるサイトの例
ただし、こうした仕組みを導入し活用している自治体はないと思います。学校、教育現場でのデータ活用の取り組みは、このあたりから始めるべきです。例えば、アレルギーのある子どもは誰で、そのデータと欠席情報、学習情報をうまく合わせることで、その子どもが入院しなくてはならなった場合などに授業に遅れないためにどのような対処が必要なのか、データに基づいて判断できます。このようなデータ活用の仕組みの整備をしていかなくてはいけないと考えます。
文部科学省では、教員の働き方改革を推進する目的で、欠席はウェブで連絡、学級通信はオンラインで配布、面談もオンラインにすることで、業務を何時間削減できるかといった試算をしています。
こうした取り組みは、そもそも国がやるのではなく、学校の設置者である市町村が工夫してやるべきことですが、それができていないのが現状です。そこで、まずは行政と教育委員会を情報化し、データを共通フォーマットで共有できるようにすることが大切です。
これまでは、「行政を超えて」情報を共有することは想定されていませんでした。その結果、個人情報保護に関する条例も「自治体の数だけ存在する」状況で、いざ国がデジタル化を進めようとなっても、すぐにはできない現実があります。
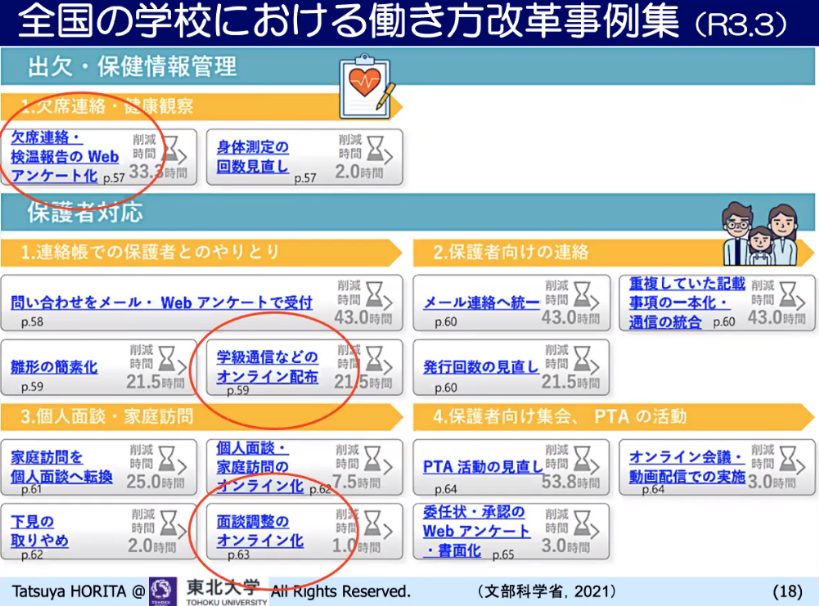
▲スライド3・文部科学省の学校における
働き方改革の事例集
同様の課題が、デジタル教科書と教育データ利活用にもあります。さまざまな垣根を越えてデータを利活用できるように国が整備しようとしている状況です。子どもたちがデジタル教科書で学べるようになるまでには、まだ数年かかると思います。教育に関する法律の多くが紙の教科書で学ぶことを前提にしているので、法改正をしなくてはならず、それには国会を通さないといけないので、ひとつひとつの改正に何年もかかってしまいます。だからこそ早く始めないといけないのですが、まだなかなか先に進めない状況です。
公教育データは「誰のもの」か
文科省の「教育データ標準」の枠組み
そうした中でのデジタル化、データ利活用の取り組みの一つとして、学習指導要領のコード化が実施されました。「学習内容にIDをつけた」ということです。告示時期、学年など細目に合わせ、学習指導要領の文章にナンバーがついています。コード化の目的は、あるデジタル教科書のあるページが、学習指導要領のどこに対応しているか分かるようにして、その対応しているコードと同じコードを持っているデジタル教材や問題集、博物館のアーカイブなどをリコメンドして出せるようにしていこうというものです。これが整備されつつあります。
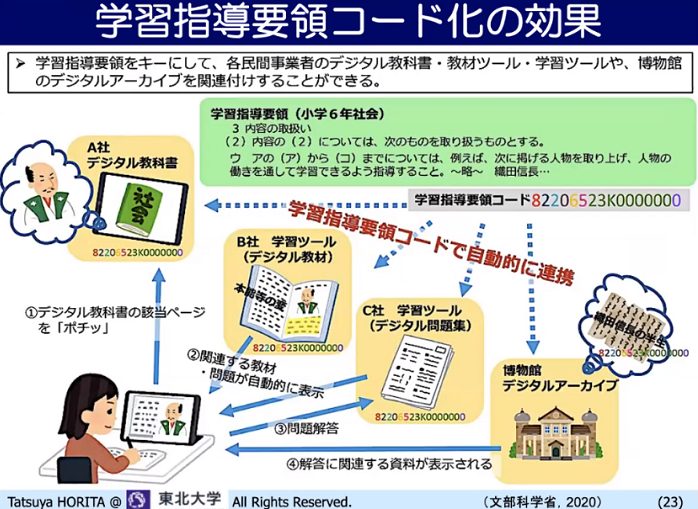
▲ スライド4・学習指導要領のコード化による
実現できるデータ連係のイメージ
学習指導要領は大綱的な文書なので、教科書のページに「1対1」では対応しているわけではありません。そのため、各教科書会社や教科書関連業界の何らかの取り決めや独自の業界ルールがないと相互リンクが簡単にはできないのです。それを国が決めてしまおうという意見もありましたが、教科書会社の自由度が奪われてしまうし、そこまで国が管理しなくてはいけないのかという議論もでてきました。そうした議論を経て、「学習指導要領のコード化」が実現しています。コードの後ろにゼロがたくさんありますが、これはいずれ色んなデータを付与できるようにしておこうということです。
教育データの利活用のイメージですが、例えば1時間目でどんな内容を学んだとか、教科書はどこまで進んだとか、どこの教材会社のドリルを何番まで進めたなど、学校で回収できるデータを公教育データと呼んで、それを「希望者が個人で活用する」というものです。
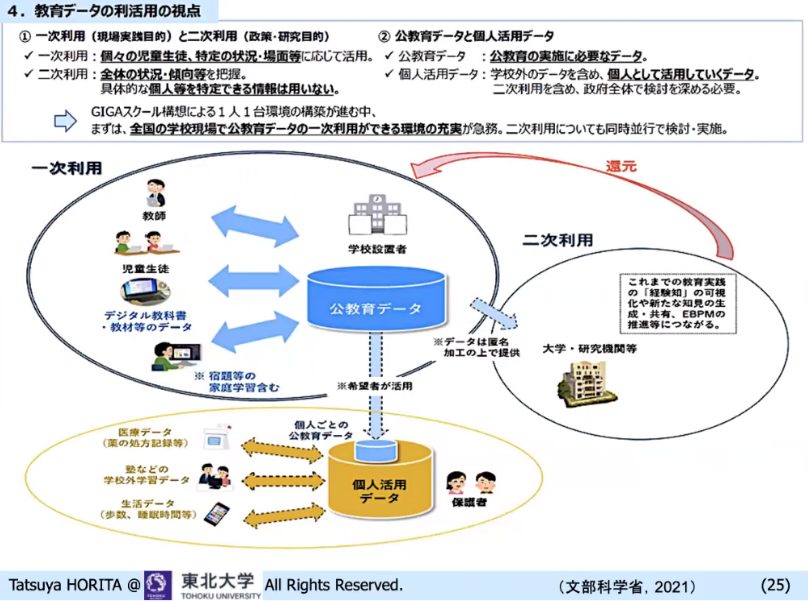
▲ スライド5・教育データ利活用のイメージ
問題は、この公教育データは誰のものかということです。児童生徒の学習の履歴は、第一義的には児童生徒のものですが、今まで子どもたちの学習の成果を参照して先生たちは成績をつけていたことを考えると、いったんは学校で保持し、それを切り出して個人のデータになるような形にするのが適切だと考えられます。
ただ学校の公教育データから取り出された個人の公教育データは、塾のデータや医療のデータ、生活習慣のデータと組み合わせたりすると、何らかの新しい相関が見出せたり、新しいリコメンドができることが考えられます。ここを進めていく必要があります。一方で大学とか研究機関では、もっとマクロにこのデータを解析して、政策に還元するようなこともしていくべきです。そのために、どういう利用想定が考えられるかを、日本学術会議や文部科学省が出しています。学習者、教員、保護者、政策立案者、研究者、市民などミクロからマクロまでさまざまなデータの利用先が想定されます。

▲ スライド6・学習データの利用先は
学習者、教員、保護者、政策立案者、研究者、市民など
ミクロからマクロまでさまざまに想定される
データの利活用については、教育以外の分野、例えば交通分野では交通系ICTカードにより、何時何分に50代の男性がどの駅からどの駅まで乗ったなどの情報がビッグデータとして利用されています。データを解析することで電車の本数を決めたり、駅のどこにエレベータをつけるべきかなど、社会の状況判断と環境改善に使われています。教育のデータもうまく収集できれば、子どもたちの成長の実態をうまく捉えることができるのではないかと期待がされています。
そのために決めておかなくてはいけないことはたくさんあります。まず子どもたちを識別できるようなIDを付与して、小学校から中学校、高校に行ってもそれを紐づける仕組みが必要です。小学校は公立で中学は私学に行って、高校は県立に行ったなど、設置者が違う場合、それをどうやってまたいで管理するか、具体的な方針はまだ決められていない状態です。
ただ、同じ校種にいる場合は、児童生徒の情報はずいぶんID化されてきています。今後は、設置者が違う場合にどうやってデータを利活用できるようにするのか、行政によってその調整が進められていくでしょう。教職員の情報も学校の情報も同じ状況です。今まで、学校にIDはつけられていませんでした。たとえば、全国学力・学習状況調査のときにIDが必要になりますが、受託業者が毎年違うので、毎年ナンバリングが違うということが起きていました。このような実態を踏まえて、文部科学省では「教育データ標準」の枠組みを示しています。
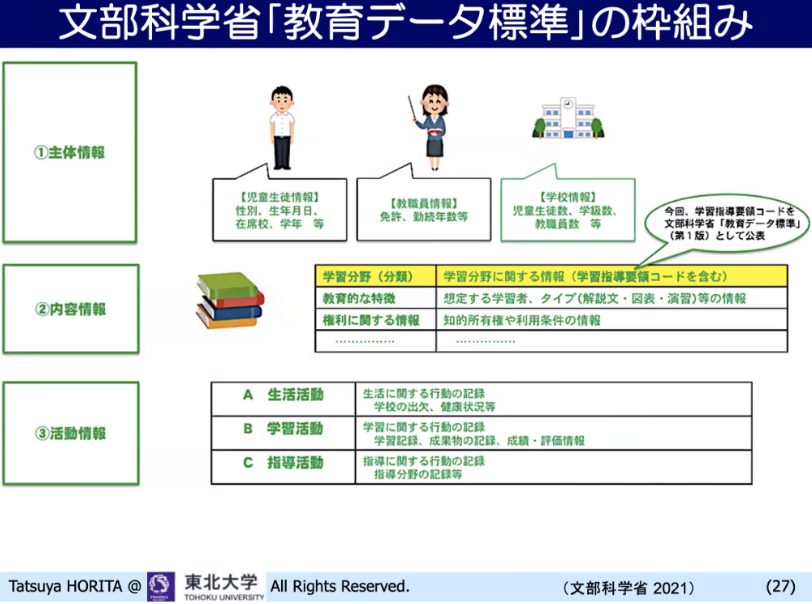
▲ スライド7・文部科学省による教育データ標準の枠組み
学習ログの分析で何が分かるのか
このように教育データが揃った際には、それらのデータを解析することで、どのようなことがわかるのでしょうか。学習ログの分析では、ある小学校の英語の授業で、前の時間に教えたことをGoogleフォームで先生が簡単な問題にして小テストをし、理解度を自動集計しました。結果を児童たちと見ながら、誰がどこで間違ったとか、クラスの実態を把握しながら先生がもう一回教えた方がよさそうなところを確認しながら進めているという事例です。毎時間、最初の3分でやっています。このように学習ログを収集できれば、データに基づいた取り組みができます。
以前はこうした取り組みを紙の小テストで実施していました。先生がプリントして作り、配り、子どもにやらせて回収し、採点して、全体の様相が分かるのは「授業の後」でしたが、今はクラウドツールができたので、こういうことが簡単にできるようになりました。
また、小学生向けのキーボード入力のスキルを高めるサイトでは、利用を申し込むと事務局からクラス全員のIDとパスワードが送られてきます。先生が子どもたちにそれを渡して、子どもたちはログインする。レベルが30級から初段まであり、2021年7月末時点でユーザー数は58万人に達しています。日本の小学校の16%がこれを使っています。先生が自分のIDでログインすると、自分のクラスの子どもの学習状況が確認できて、アクセス日とか、誰が何回失敗して何回目に25級に受かったなどが分かります。
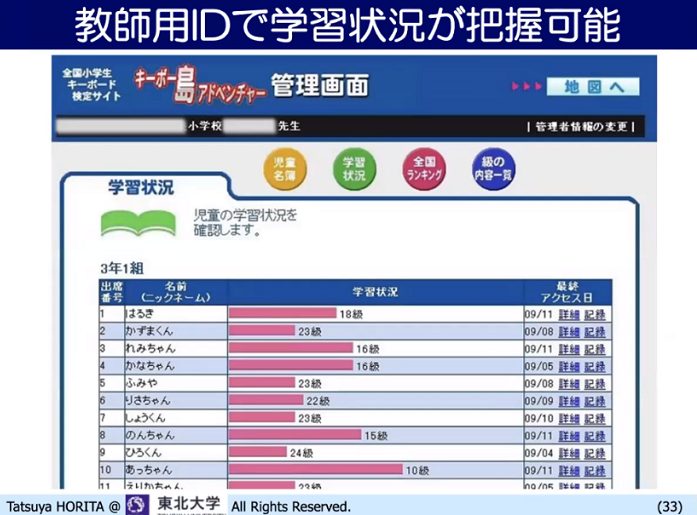
▲ スライド8・キーボード検定サイトの教師用管理画面
学習ログの分析をすると、例えば一番よく使われているのは6月で、その後2学期に安定的に使っていくという様子が見て取れます。また午前中より午後が多いとか。夕方やっている子や夜中にやっている子もいるなどの実態も把握できます。
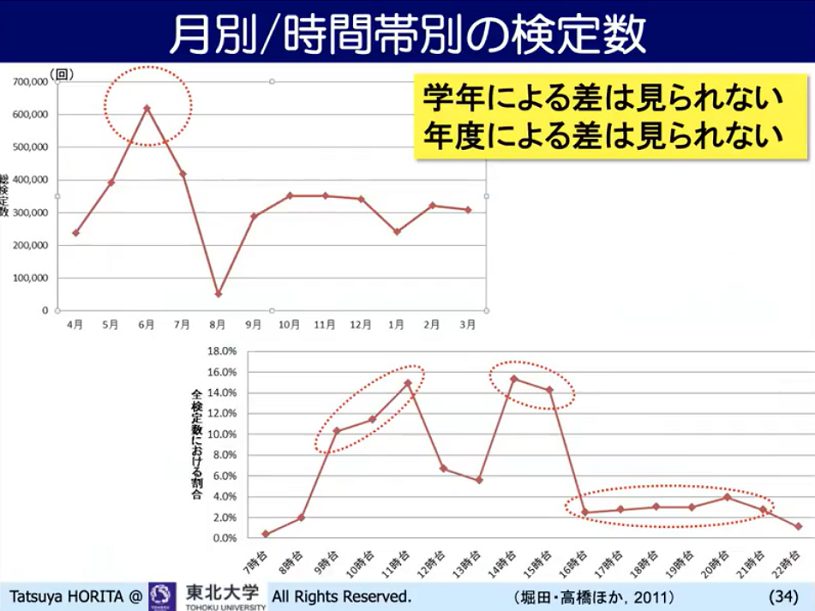
▲ スライド9・キーボード検定サイトの利用グラフ
年度によってグラフの形は、ほぼ同じです。日本の子どもの利用実態が綺麗に出ている例といえるでしょう。何年生の子が何級まで何%到達するか見ていくと、学年が高い方が早く多くの割合で到達することが分かるし、何級が難しいのかも分かります。級の調整などもデータをもとにできます。こうしたラーニングアナリティクスは、九州大学や京都大学でさまざまに研究されています。東北大学でも、ラーニングアナリティクス研究センターを立ち上げました。
デジタル教科書は今年から始まったばかり
データ分析と利活用にはまだ時間がかかる
中等初等教育では、東北大学大学院情報科学研究科の我々の研究室と東京書籍などが荒川区の教育委員会と一緒に、2017年に共同研究で学習ログの収集をしました。例えば、デジタル教科書はどこかをクリックするとそこが大きく表示される機能があります。そこで、どこがよく大きくされるのかを調べれば基礎研究として意味があるのではないかという取り組みです。そのログを取っていった結果、デジタル教科書の利用は秋に多かったという結果が出ました。秋になると、学校行事などで様々なことに挑戦するという雰囲気が出ているのかもしれません。
その他にも算数の教科書の見開きで、どの部分がどのくらい大きくされているかを見ると、一番大きくされているのは円グラフでした。その上に学校の写真が掲載されているのですが、これは学習内容には直接的な関係がありません。子どもたちにイメージを与えるために学校の写真を載せているだけですが、それをボタンにしたためにそこをクリックする子がけっこういるということが分かりました。こうしたデータは、デジタル教科書を作る側の作り方の工夫にフィードバックできます。
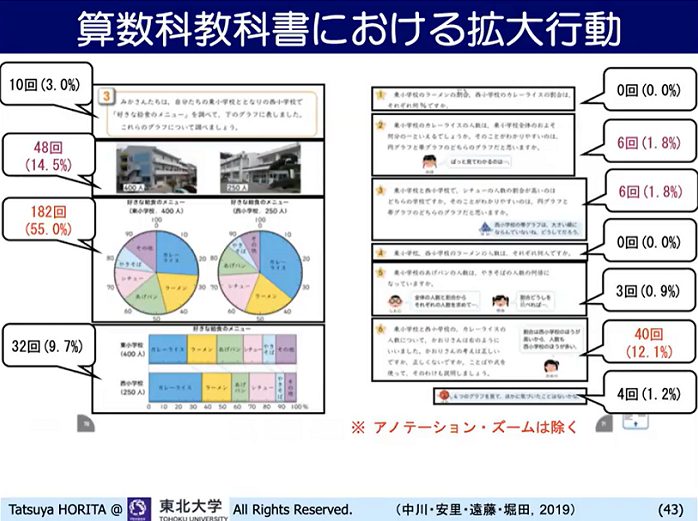
▲ スライド10・算数の教科書で子どもたちが、
どこを拡大表示させたのかが一目でわかる
また社会科では写真や地図を大きくすることが多いです。データの形式の問題なのか、内容と関係して大きくされるのか、これからもっと解析されるべきでしょう。ただ、大きくしていれば学習しているのかということはまだ分かりません。こうしたことも今後、研究する必要がありますが、そもそもデジタル教科書は今年から使われ始めたので、研究も始まったばかりです。データ駆動まではまだ少し時間がかかるでしょう。
例えば17人の子どもを比較して、デジタル教科書のポップアップやズーム、ページオープンなどをどのくらい使っているかを見ると、ばらつきがあります。61回クリックしている子から7回しかクリックしていない子もいるのです。ただし、7回しかクリックしていない子が勉強していないとは言い切れません。同様に、ズームの機能をよく使っている子は、勉強熱心なのか単にズームが好きなのか分かりません。1回の授業の分析だけでは何も言い切れないのが現状です。もっと研究の積み重ねが必要でしょう。
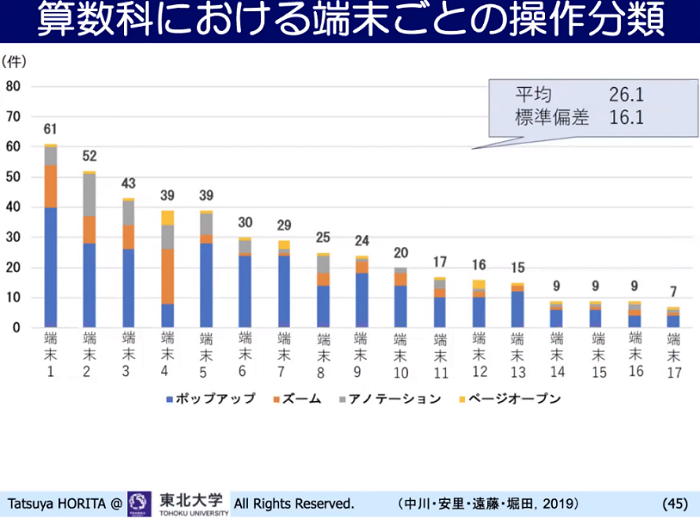
▲ スライド11・児童別(端末ごと)のデジタル教科の操作分類、
端末4の子どもは、他に比べてコンテンツを
ズームさせる操作が多いことなどがわかる
デジタル教科書のページでどこが多くクリックされたかをヒートマップ化すると、みんなが興味があるところが分かります。子どもたちがどこをよく見ていたか分析できれば、教科書会社によっては有用な情報ですし、社会科教育をやっている人はここから学べることがあるでしょう。「どこをどのくらいクリックした子が、学力が高いのか」まで分かってくれば、どういった資料に重きをおいて指導すべきか見出せるようになるかもしれません。ただ、この試みはこれは始まったばかりです。

▲ スライド12・社会科のデジタル教科書を
ヒートマップ化した例
ID付与や学習ログの利用権限など
データ駆動型教育の実現に向けて課題は
まだ「始まったばかり」の教育データの利活用ですが、今後、さらに推進していくためには解決すべき課題があります。まずは、学習指導要領コードは「桁が粗く」、単元内容をきちんと反映できるほどに細分化されていないことです。教科書会社と研究者が協力して、単元内容情報や問題別の特性情報を付与していかなくてはなりません。2つめの課題は、学校IDや教員ID、学習者IDをどう付与するか。3つめは、デジタル教科書とデジタル教材の自動リンク。教科書と教材はだいたい違う会社が作っているので、そこが課題になります。
4つめは、デジタル教科書の配信プラットフォームが教科書会社によって異なることです。また、デジタル教科書の学習ログの回収先は学校にすべきか自治体にすべきかという問題もあります。5つめは、収集した学習ログをどこが責任を持ってクラウド上で管理・保管するのか。そして、「誰がその学習ログを見ていいとする」かも考えなくてはなりません。学習ログの収集と分析の権限の割り当てについては、まだ曖昧です。6つめは、ミクロな学習ログとマクロな成績データがある中で、どこをどのように研究していけばいいかという問題です。担任は、児童一人ひとりについてミクロなデータを把握したいと考えるでしょうし、一方で研究者はもっとマクロに、例えば「5年生の算数で最も時間がかかっている単元はどこか」といったことを研究したいと考えるでしょう。
7つめは、校務支援システムなど数値化された評定情報が入っているシステムと、1回ごとのクリックなどの情報をどう連携していくかといった「データ連携」における課題です。8つめは、全国学力・学習状況調査のCBT(Computer Based Testing:コンピュータを利用した試験)化です。一方で、単純な解析から始めた方がいいのではないかというのが9つめの課題です。小学校4年で面積の勉強が始まりますが、だいたい何月何日ごろから始める学校が何%とか。例えば11月の2週目くらいがピークと分かったら、教材会社はそのころに面積の教材が前に出てくるようにすれば良いでしょう。マーケティングの視点からできればいいと考えます。10番目の課題は、進度の差は学力の差になっているのかということです。あわせて、地域や家庭など社会経済的な差と学力との関係が分かってくれば、どこの地域に手厚く予算をつけるなどして、学力向上の手助けをしていけばいいのか、マクロに分かるでしょう。

▲ スライド13・教育データ利活用の10の課題
>> 後半へ続く




