教育データの活用にどう取り組み、エビデンスに基づく教育を実現するか
第32回オンラインシンポレポート・前半
活動報告|レポート

概要
超教育協会は2021年1月19日、京都大学 学術情報メディアセンターの緒方 広明氏を招いて、「教育データの利活用とエビデンスに基づく教育の実現に向けて」と題したオンラインシンポジウムを開催した。
シンポジウムの前半では、緒方氏が、「ラーニングアナリティクス」と同氏のグループが開発している基盤情報システム「LEAF」に関するプレゼンテーションを行い、後半では、超教育協会理事長の石戸奈々子をファシリテーターに視聴者を交えての質疑応答を実施した。その前半の模様を紹介する。
>> 後半はこちら
>> シンポジウム動画も公開中!Youtube動画
「教育データの利活用とエビデンスに基づく
教育の実現に向けて」
■日時:2021年1月19日(火) 12時~12時55分
■講演:緒方 広明 氏
京都大学 学術情報メディアセンター教授
■ファシリテーター:石戸 奈々子
超教育協会理事長
緒方氏は、約30分間の講演において、教育分野においてビッグデータを活用する「ラーニングアナリティクス」と、同氏のグループが開発している基盤情報システム「LEAF」について説明した。主な講演内容は以下のとおり。
教育ビッグデータを分析してフィードバックする「ラーニングアナリティクス」
本日は、初めに「ラーニングアナリティクス」とは何か、次に私たちが開発している「基盤情報システム『LEAF』の概要」、それから「LEAFを用いた実証実験」最後に、「エビデンスに基づく教育のあり方」と言う順序で話を進めさせていただきます。
ラーニングアナリティクスでは、最初に、授業内外で起こる「学び」のプロセスを記録します。もちろん、成績もデータの一つとして記録されますが、成績とはある時点でどれだけ理解しているかを示す、単なる「スナップショット」に過ぎません。より重要なのは、そこに至るまでにどれだけ学習してきたか、あるいは教育してきたかというプロセスで、具体的には、ラーニングマネジメントシステム(LMS)やデジタル教科書・ドリル教材などの履歴を活用します。そして、記録された「教育ビッグデータ」を分析して介入・フィードバックを行うのがラーニングアナリティクスです。
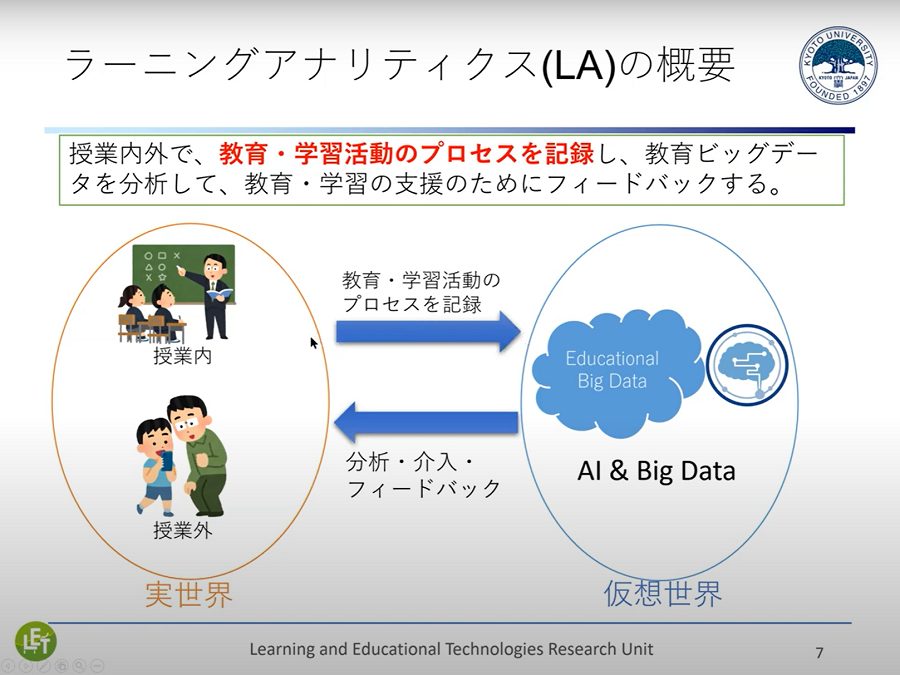 ▲ スライド1・ラーニングアナリティクスの概要
▲ スライド1・ラーニングアナリティクスの概要
ラーニングアナリティクスの研究目的は、①教育・学習効果を最大限にすること、②先生の負担を最小限にすることの2つです。
収集した教育データの使い途としては、まず、教材や問題の推薦など「学習者へのフィードバック」があります。先生に対しては、子供のつまづき箇所の発見や自動採点など負担軽減、保護者に対しては、子供の学習状況などの把握、学校など教育機関に対しては、カリキュラムの最適化やクラスの状態に合わせた教員の適正配置などを想定しています。
さらに、国全体で教育データを共有すると、政策立案者は、エビデンスに基づく教育政策の立案と評価が可能になり、研究者は、縦断的・横断的なデータを用いた学習者の成長過程の研究が行えるようになると考えています。
ラーニングアナリティクスの基盤となる情報システム「LEAF」とは
ラーニングアナリティクスを行うための基盤情報システムが「LEAF」です。
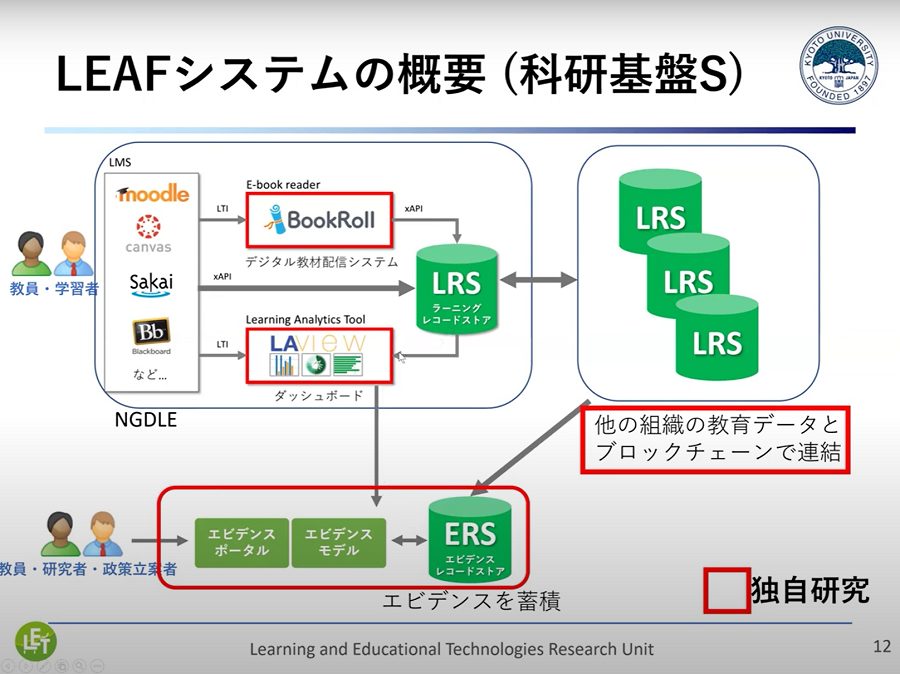
▲ スライド2・LEAFシステムのフレームワーク
少し技術的な内容になりますが、重要なのは、学校での成績や、どういった授業を選択しているかなど、組織の中での教育データを「ラーニングレコードストア(LRS)」に一元的に集めることです。その結果として、組織ごとにLRSが生成されますので、小学校・中学校・高校と進学したり転校したりすると、分散した場所に個人のデータが記録されていきます。これをブロックチェーン技術で連結していくことを検討しています。
「エビデンスに基づく教育」とは、LRSに記録され、分析したデータを元に、どういうフィードバックをしてどういう効果があったかという「エビデンス」を、エビデンスレコードストア(ERS)に蓄積し、それを国全体で共有していこうという取り組みです。日本学術振興会、内閣府、文部科学省、NEDOなどから研究費の助成を受けています。
LEAFシステムは現在、京都市内の小学校・中学校・高校のほか、全国各地の高校・大学や、台湾・インド・中国・トルコなどの大学とさまざまなデータ分析で共同研究を実施しています。

▲ スライド3・LEAFシステムの共同研究先
手書きの回答の分析や長文読解など LEAFを用いた実証実験
LEAFが実際の授業でどのように使われているか、3つの事例を紹介します。1つめの事例は、数学における手書き回答の分析です。私どもが開発したデジタル教材配信システム「BookRoll」BookRollでは、学習者が直接手書きで回答を記入できま。その後、正解したかどうか、理解度に応じた複数の選択肢から自己申告することができます。
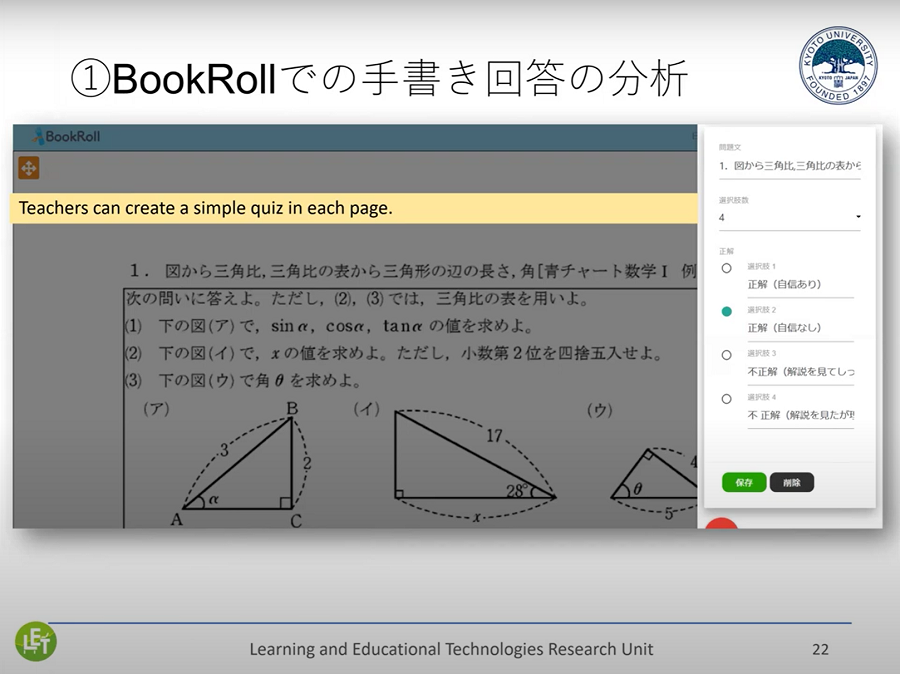
▲ スライド4・①数学:BookRollでの手書き回答の分析
手書き回答は記述プロセスが1ストロークずつ記録・再生でき、書き出しに長く時間がかかっている、つまり筆が止まって考えているところは赤、普通にスラスラ書けているところは黒で表示され、どこで消しゴムを使い書き直したのかもわかります。

▲ スライド5・手書き回答(記述プロセス)の分析
こうしたデータを元にして回答のクラスタリングが行えます。例えば、正しい解き方の回答が2グループ、間違った回答が3グループなどと分類し、それぞれのグループの典型的な回答を緑・黄・黒・青などと色分けして抜き出し、教室で学生に見せることができます。この手法はもともと、先生が紙の問題を回収し、回答を一つ一つ分類して典型的な回答を選び出していましたが、これだと時間がかかるため説明できるのは次の授業になってしまいました。これがLEAFだと作業が瞬時に行えますので、問題を提示して手書き回答を収集し、典型的な回答を例示しながら説明するまでの一連の流れを、同じ授業時間内で行えるようになりました。
また、異なる解き方で回答した学習者同士で一つのグループを構成し、双方の解き方を共有するといったグループ学習も可能になっています。
学習者が間違った回答をした時には、どの学習要素について間違えたのかを把握することが重要です。クラス全体の学習要素の理解度を可視化することもできます。右側に一部をクローズアップしてみると、「ある部分は83%が理解しているが、別のある部分はほとんど理解されていない」といったようなことがわかり、こういった状況を踏まえて次の問題を推薦することができます。
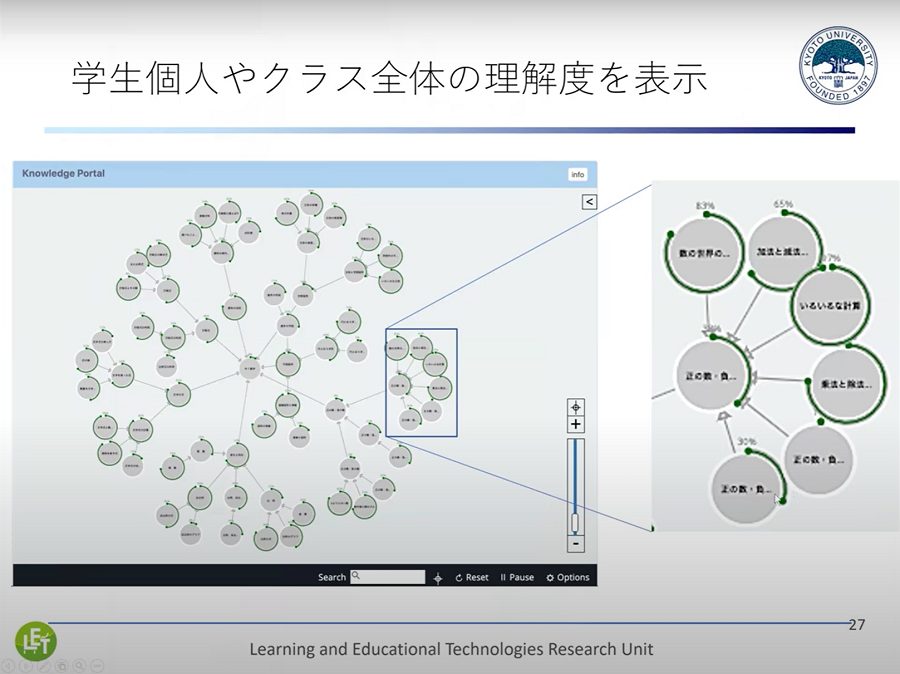
▲ スライド6・学生個人やクラス全体の理解度を表示
こういった理解度の可視化は、学習者が、自己の知識が時間の経過と共にどのように増えてきたかを確認したり、先生が、自分が担当するクラス全体がどこを理解できていて、どこを理解できていないのかを把握したりできるという意味で非常に重要です。
2つめの事例は、英語の長文読解です。紙ベースの長文読解戦略は古くから研究されていて「SQ3R」と呼ばれるモデルが有名ですが、私たちはこれをeBookに適用し、「2SQ3R」という読解戦略を提案しています。

▲ スライド7・2SQ3R Strategy with BookRoll
2SQ3Rは、まず最後まで一通り読んで全体を把握します。その時に重要なトピックには赤いマーカー(Scan)、わかりにくかった箇所には黄色のマーカーを引きます(Skim)。そして、メモに質問を書き(Question)、実際に内容をじっくり読み(Read)、自分で出した質問に対する回答し(Reply)、熟考する(Reflection)というような流れになります。

▲ スライド8・Scan+Skimプロセスのマーカー
スライド8は、クラス全員が引いた「Scan」と「Skim」のマーカーを重ねたものです。各学習者が引いたマーカー位置が、最初(左)はバラバラだったのが、2週間後(右)には、ほぼ同じようなところをピックアップできるようになっていることがわかります。
3つめの事例は、「グループ編成」です。小学校の場合、先生はグループ編成を検討するのに、最小30分~最大2時間程度かかっていると言います。これに対し、小テストの成績や各学習要素の理解度、これまでのグループでの発言度合いといったデータを蓄積し、それらのパラメーターを利用することで、短時間で自動的にグループを作るという研究をしています。NEC製音声認識デバイスを利用した共同研究事例で、会話の中で「何回発話したか」という情報を元にグループ学習への関与度合いを判断し、それを次のグループ編成に活かしていく研究を行っています。
「エビデンスに基づく教育」を実践していくために必要なこと
最後は「エビデンスに基づく教育」です。エビデンスの抽出というと、これまではグループを比較したり、アンケート調査や成績データなどを用いたりするものがほとんどでしたが、私たちが研究しているのは、LMSやデジタル教科書の利用履歴といった「プロセス」の客観的なデータを用いたエビデンスの抽出です。
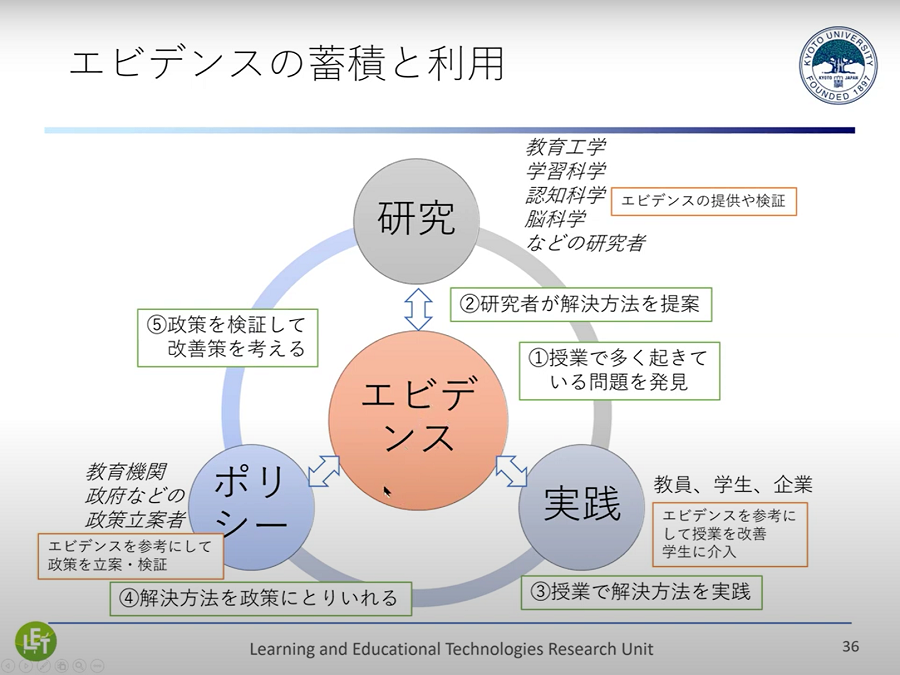 ▲ スライド9・エビデンスの蓄積と利用
▲ スライド9・エビデンスの蓄積と利用
やろうとしているのは、さまざまな分野の研究者(「研究」)、実践する先生や学生(「実践」)、教育委員会の方などの政策立案者(「ポリシー」)が「エビデンス」を共有する仕組みの構築です。
それにより、現場で起きている問題点を把握し(①)、研究者が解決方法を提案して(②)、現場が実践して成功したことをポリシーとして提案し(③)、政策立案者がそれを取り入れ(④)、その結果を検証してまた実証していく(⑤)というように、エビデンスを中心にして関連する人々を結びつけられるサイクルを考えています。
本日の内容をまとめますと、コロナ対策やGIGAスクール構想で教育現場のデジタル化が進展し、大量の教育データが蓄積されるようになっています。それをうまく活用して、教育・学習の改善のために有効利用することが必要になってきています。それにより、教員の経験や直感に頼らない、教育データの科学的な分析に基づく教育が実現できればと思っています。
>> 後半へ続く





