AIの進化でよりインタラクティブな教育に第116回オンラインシンポレポート・前半
活動報告|レポート

概要
超教育協会は2023年3月7日、東京大学大学院工学系研究科人工物工学研究センター/技術経営戦略学専攻教授の松尾 豊氏を招いて、「AIの進化で教育はどう変わるのか?」と題したオンラインシンポジウムを開催した。
シンポジウムの前半では、松尾氏が、注目を集めている対話型AI「ChatGPT」をはじめとするAIの現状や、AIの進化で教育がどう変わるかについて講演し、後半では超教育協会理事長の石戸 奈々子をファシリテーターに質疑応答を実施した。その前半の模様を紹介する。
>> 後半のレポートはこちら
■日時:2023年3月7日(火)12時~12時55分
■講演:松尾 豊氏
東京大学大学院工学系研究科人工物工学研究センター/技術経営戦略学専攻 教授
■ファシリテーター:石戸 奈々子
超教育協会理事長
松尾氏は、約40分の講演において、AI、対話型AI「ChatGPT」の現状、AIの進化が教育にもたらす変化について説明した。主な講演内容は以下のとおり。
AIの歴史を振り返ると、第一次、第二次AIブームがあり、2010年代から第三次のAIブームになっています。
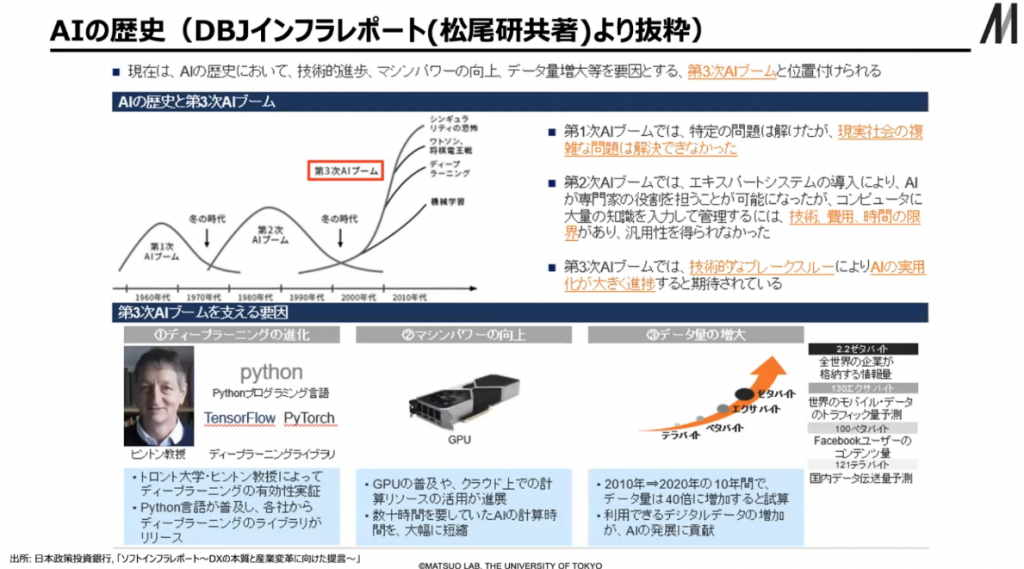
▲ スライド1・AIの歴史
第三次AIブームの中心になっているのが、ディープラーニングという技術です。人工知能の分野は非常に幅広いですが、人工知能の中の一部が機械学習という分野で、この機械学習の一部がディープラーニングという包含関係になっています。ディープラーニングはもともとニューラルネットワーク領域で研究されていましたが、これは人間の神経回路を模したモデルを用います。各ニューロン、各ユニットは非常に単純な処理をします。それが集団として集まることによって、入力Xを、出力Yにと色々な形で変換することができるようになります。これを誤差が少なくなるようにデータに合わせて調整するのが誤差逆伝播という方法です。これは昔から変わっていないやり方といえます。
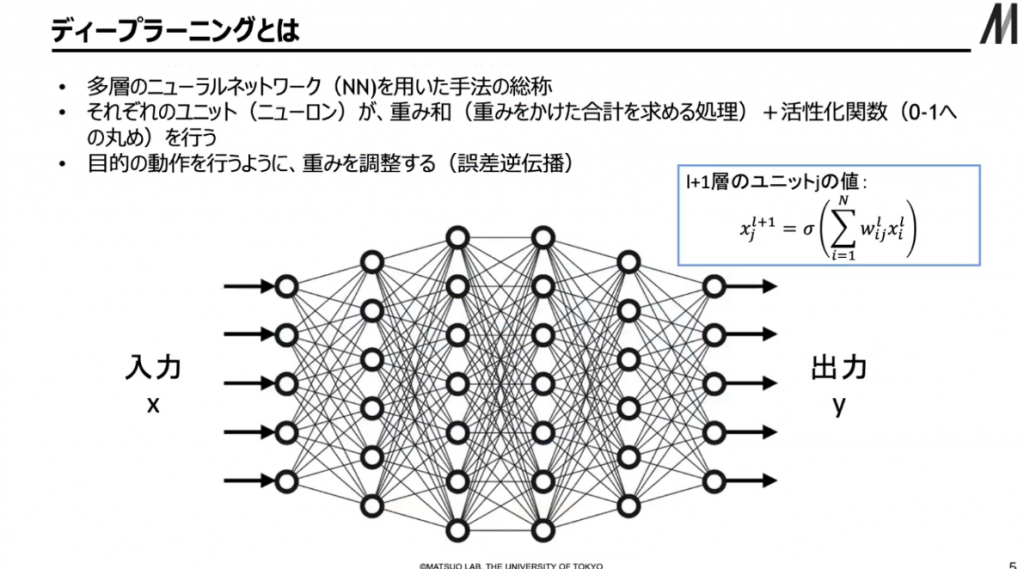 ▲ スライド2・ディープラーニングのしくみ
▲ スライド2・ディープラーニングのしくみ
ディープラーニングがめざましい発展を見せたのが2012年です。画像認識で大きな性能の飛躍がありました。2015年くらいから様々なアプリケーションで使われるようになってきています。顔認証や画像診断、音声認識などでも当たり前に使われるようになってきています。
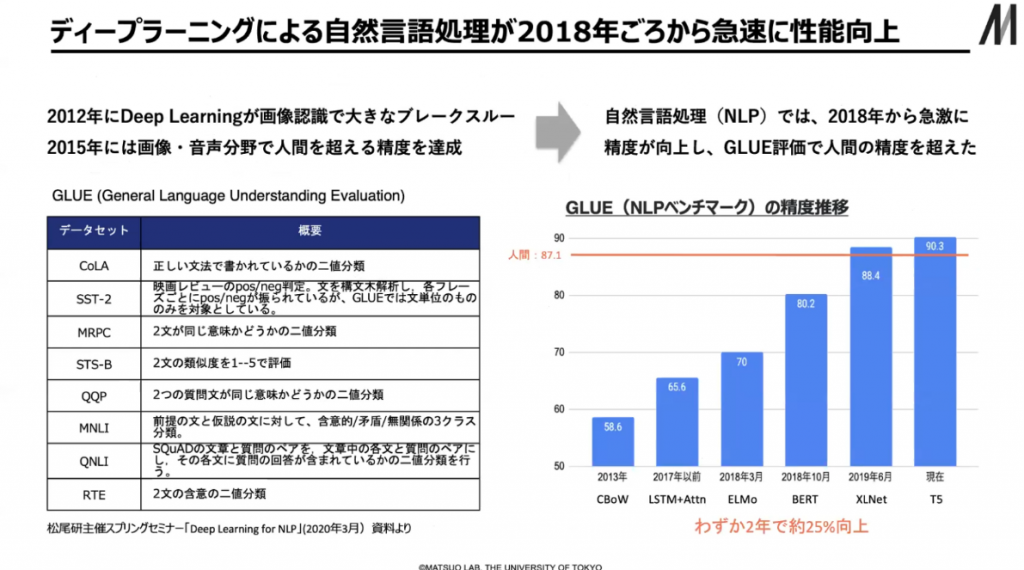
▲ スライド3・ディープラーニングの進化
一方、自然言語処理でもディープラーニングの活用が進み、2018年頃から精度が飛躍的に向上してきました。そのきっかけになったのがトランスフォーマーと呼ばれる技術で、2017年に提案されたものです。「Attention is All You Need」という有名な論文で、アテンションという機構を大規模に使ったトランスフォーマーが提案されています。アテンションとは、ニューラルネットワークで処理して上がってきた情報をもとに、ニューラルネットワークのどこに注目を当てるかを変える仕組みのことです。
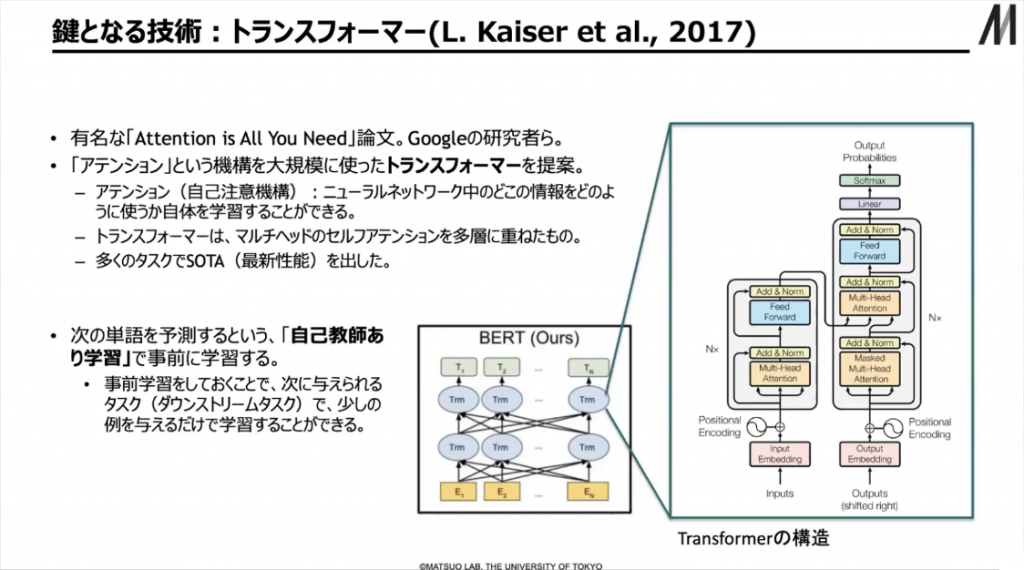
▲ スライド4・トランスフォーマーが
鍵を握る技術である
もうひとつ重要なのが「自己教師あり学習」で、これは従来、「教師なし学習」と言われていたもののひとつです。なぜ「自己教師あり学習」というのかというと、例えば自然言語のテキストを与えると、このテキストだけから「教師あり学習」をするからです。この自己教師あり学習を事前にやっておくと、後から与えられたタスクに対しての学習精度が一気に上がるということが知られています。
2020年夏に登場して話題になった対話型AI「GPT-3」
2017年のトランスフォーマーの発明以降、次々と新しいモデルが提案されてきました。有名なのがBERT、RoBERT、DistlBERT、XLNetなどです。BERTのサイズは340ミリオンですが、これはBERTのモデルにおけるパラメーターの数が3億4,000万あるということです。
パラメーターの数は、ニューラルネットワークでいうと一個一個の重み、図で見ると線の数にあたります。それが3億4,000万あるということです。つまり、チューニングできるパラメーターが3億4,000万あるのがBERTです。
2020年に出た対話型AI「GPT-3」は、1,750億パラメーターで、桁違いに大きいパラメーターを持つモデルでした。
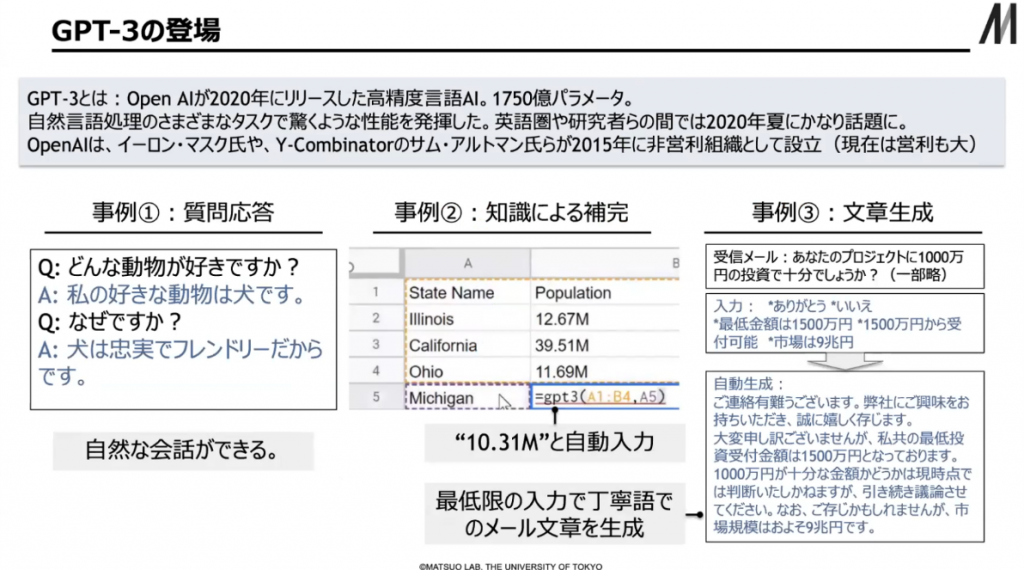
▲ スライド5・話題になったGPT-3
これを世に出したのがOpenAIです。GPT-3は2020年夏に、人間が入れた問いに対して的確に答えることができるということで、英語圏の一部の研究者の間でかなり話題になりました。知識による穴埋めもできるほか、キーワードを入れるだけで流暢な文章を生成することもできます。
2020年に同時に明らかになったのが「スケール則」で、これも極めて重要な法則です。これは、パラメーターの数を横軸にとり、縦軸にテストの時のエラー率をとると、パラメーターの数を上げれば上げるほど、エラー率が下がっていくという法則です。つまり大きなモデルを使って大きなデータセットで大きな計算機で学習させれば、性能が上がり続けるという単純な法則ともいえます。GPT-3の時点で、1回学習するのに推定で数億円から数十億円かかっているといわれていました。その上でこのスケール則が発見されたので、現在では「いかに大きなお金をかけるか、リソースをかけるか」という戦いになっていきます。
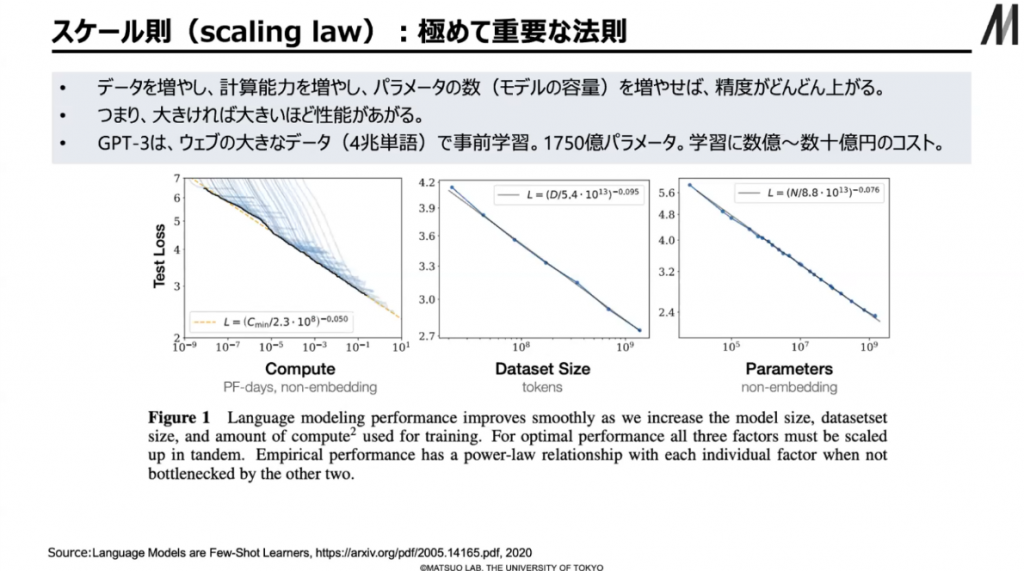
▲ スライド6・極めて重要なスケール則
2021年には2,800億パラメーターのGopherというのが出て、昨年はGoogleからPaLMが出ました。これは5,400億パラメーターで、次々と大きなモデルが登場しています。大きなモデルであればあるほど、性能が向上しています。PaLMでは、ジョークを入れるとこのジョークがなぜ面白いのか説明してくれるほどです。
また、論理的な推論ができます。質問に対して答えるだけでなく、なぜその答えを導いたのかをロジカルに説明することができるのです。
公開からわずか2カ月でユーザーが1億人を突破したChatGPT
大きくすれば性能が上がるということが判明しているので、開発競争を繰り広げられ、巨大なものが次々と登場しました。その中で、2022年の11月30日にChatGPTが公開されました。

▲ スライド7・2022年11月にChatGPTが登場
ChatGPTは公開から1週間で100万ユーザー、2カ月で1億ユーザーに到達しました。これは史上最速です。FacebookやTikTokより早くユーザー数を伸ばしています。ベースになっているのはGPT-3です。そのため、基本的には2020年の夏に出たものとあまり変わりません。ただそれを一般のユーザーが使えるようにしたことで、一気にユーザーが増えたのです。
例えば、「日本全体にイノベーションをもたらすにはどうすればよいですか」と入れると、「日本におけるイノベーションを促進するためには、政府がより効果的な政策を推進し企業家やビジネスに対する支援を強化することが重要。また教育システムを改革して創造的思考や問題解決の能力を高めることが必要。さらに企業が研究開発に投資することを奨励することも有益です」と、模範解答的な答えが返ってきます。
もっと会話を続けることもできます。スタートアップによるオープンイノベーションについてどう思いますかと聞くと、「スタートアップによるオープンイノベーションは新しいアイデアや技術を生み出すことによって社会をよりよいものにするための活動です。私はこの取り組みが社会の発展と成長に重要な役割を果たすと考えています」と答えます。
スタートアップと大企業はどんな関係であるべきですかと聞くと、「相互に補完的な関係であるべきです」と答え、大企業は何をしたらよいか具体的に教えてもらえますかと聞くと、「大企業はスターアップに投資することで、その成長を支援することができます。スタートアップとの協力を通じて、新しいビジネスモデルやサービスを開発することや、市場に新しい価値を提供することができます」など非常に的確な答えが返ってきます。
「なりきり力」や「ディベート力」もあるChatGPT
ChatGPTはどのように学習しているかというと、3ステップで構成されています。1つめが「教師あり学習」で、質問に対して答えを用意します。このデータセットを用いてファインチューニングします。事前学習したGPT-3やGPT-3.5を使ってやるということです。
ある程度、適切な回答が出せるようになったところで、2つめのステップとして実際に会話をします。人間と会話をした結果、その会話がよかったかどうかを〇×をつけてもらいます。その〇×を予測するような報酬の関数を学習します。こういう時には〇がもらえる、こういう時には×だという報酬のモデルを学習するということです。
3つめのステップでは報酬のモデルを用いて、報酬が高くなるような行動の仕方、回答の仕方を学習していきます。結果、報酬が高くなるような回答をします。報酬を人間が作っているので、「人間の判断」をChatGPTは反映しています。人間のフィードバックに基づいた強化学習ができるということです。
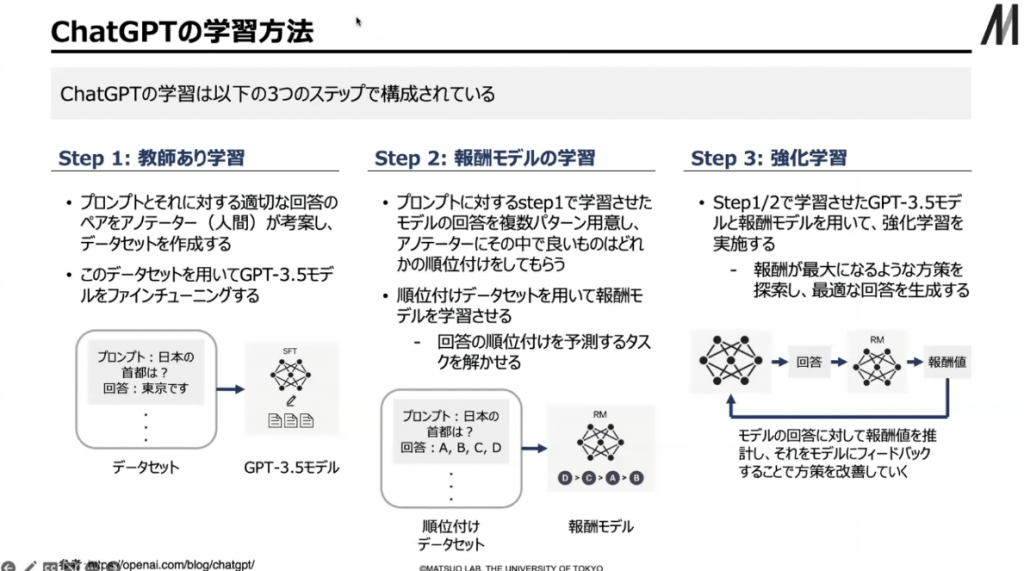
▲ スライド8・ChatGPTの学習方法
ChatGPTの活用で、海外では宿題をChatGPTにやらせるのが問題になっていますが、日本でも同じような問題が出始めています。私が面白いと思っているのは、ChatGPTの「なりきり能力」の活用です。
ChatGPTに、コールセンターのオペレーターとしてふるまってくださいと伝えます。さらに詳しく、「そこは冷凍弁当の宅配を行っている会社です。お客様には冷静に丁寧に自信をもって対応してください。お客様の不満を解消することを目指してください」と入れると、ChatGPTはまず「お客様のお悩みをお聞かせください」と言ってきます。そこで、「今日の弁当が届いていませんが、何かありましたか」などと質問すると、「ご心配をおかけして大変申し訳ございません、お届け先やお名前やご注文内容をお伺いします」と返ってきます。驚くべきことに、何のトレーニングをしなくてもコールセンターの担当者のように振る舞い始めるのです。

▲ スライド9・ChatGPTのなりきり能力
ディベートもできます。テーマ「AIと規制について」を、賛成チームと反対チーム両方を一人二役でこなしてくださいというと、一人二役をこなします。賛成チームと反対チームというように交互に発言し、一方が納得したり反論できなくなったりした時点で終了となります。
AIが人類の生活をより豊かにするためには規制が必要であるというのが賛成チームの論点です。一方、反対チームの論点は、規制が過剰になるとAIや技術の進歩が妨げられるというものです。このように反対チームと賛成チームに分かれて議論を進めていきます。各チームが考える適切な規制と過剰な規制について具体例を挙げて論じなさいというと、例を挙げてくれます。最後に両者が合意できそうな折衝点はありますかと聞くと、賛成チーム反対チームとも、適切な規制が必要であると考えていて、適切な規制が合意できそうな点というところまで提示してくれます。
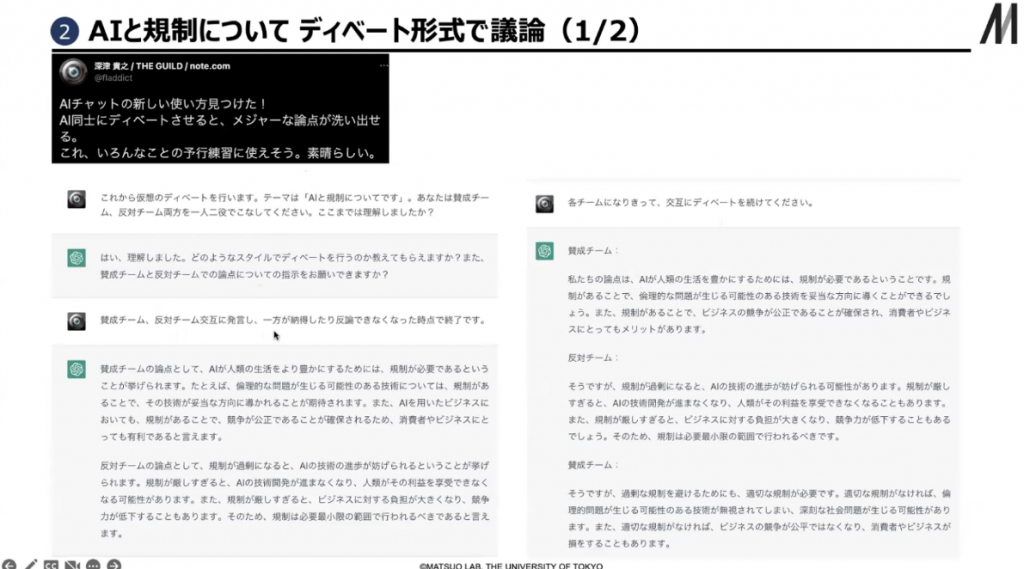 ▲ スライド10・ChatGPTが一人二役で議論
▲ スライド10・ChatGPTが一人二役で議論
英文校正やプログラミングのバグの発見など様々な使い方ができる
英文校正もできますが、普通の英文校正と違って、色んな文脈を織り込めるのが特徴です。例えば、「以下の文章は、厚生労働省が配る資料の外国人入国者向けの健康上の注意事項を通知する文章です」という注釈のある英語の文について、ChatGPTに「この文章を、極力文意を変えずまた文章構成を変えずに次の条件を満たす文章に書いてください。公共機関が書くような礼儀正しく丁寧な英語の文章、読んですぐ理解ができる、誤解が起きない直感的で読みやすい文章、ネイティブが書いたようにしか見えない流暢で自然な英語の文章にしてください」と依頼すると、みごとに英語が書き変わります。

▲ スライド11・ChatGPTによる英文校正
プログラミングにも使えて、バグを発見することができます。プログラムのソースコードを入れて、バグがあるか探してくださいと入れると、「このプログラムには次のようなバグがあります。変数strがforループ内で参照されるたびに新しい文字列への参照を持つようになっています」などと答えてくれます。
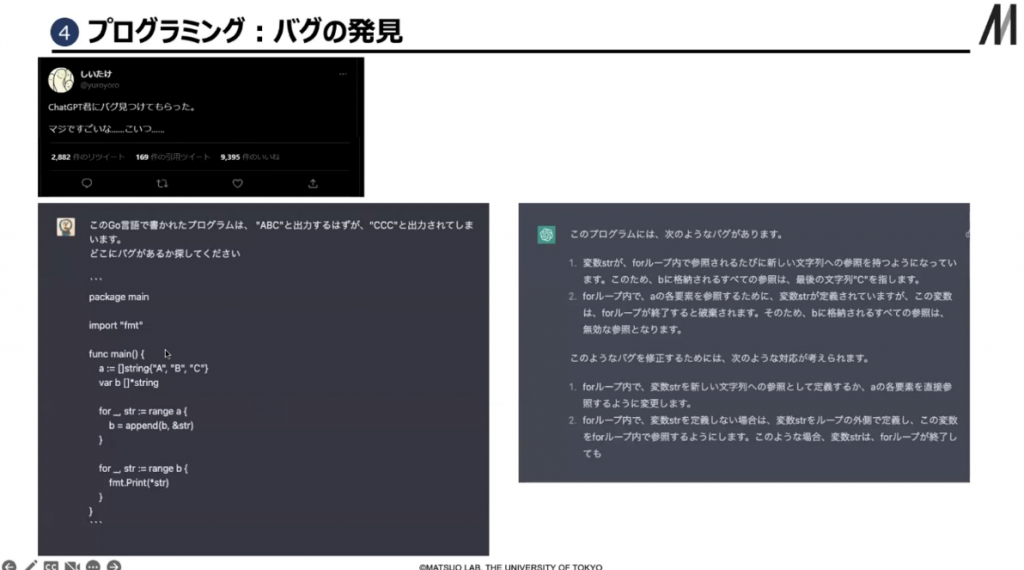
▲ スライド12・ChatGPTによるバグの発見
ChatGPTは色々な使い方ができます。ChatGPTはインターネット上の情報を学習しているため、基本的にはインターネット上の情報を、今のコンテキストにおける類型に分類し、この類型を組み合わせて答えています。ある種の混ぜ合わせのため、厳密に言えばクリエイティビティはありません。
海外ではおもに学校や科学論文などで色々な影響が出始めていて、ニューヨーク州やシアトル州の公立学校では、ChatGPTの宿題への利用が禁止されました。ただ、教育ツールとしては積極的に活用しようという動きもあります。なお、科学論文では、機械学習のトップ会議であるICML(International Conference on Machine Learning )がチャットGPTを使って執筆することを禁止しています。
技術の蓄積+ソーシャルな相互作用の2つの要因が急速な普及につながった
ChatGPTは人間が明示的に〇×をつけて、人間にとって好ましい対話が生成できるようになっています。今までの対話型AIは、リリースするとユーザーがいたずら心で色々なことを言わせようとして、それにみごとに引っかかって、誹謗中傷や炎上でサービス停止となってしまうことが多くありました。そこで、ChatGPTは誹謗中傷や差別的発言をしないように注意が払われています。
強化学習によるトレーニングがうまく働いていて、それによって多くの人が使っても支障がないものになって、その結果、多人数による創発的な使われ方が起きたと思います。つまり、「ChatGPTという現象」は、技術の蓄積で着々とパラメーターの数を上げながらレベルが上がってきたという側面と、それが一気にみんなが使えるものになって、さらに炎上しないものになり新しい使い方の発明が相互作用を生み出しながら起きたという側面を持っていると思います。色んな使い方があることについて、OpenAIも、他の研究者や技術者も驚いています。GPT-3が実はこんなことまで学習していたんだということが改めて明らかになっているということです。

▲ スライド13・ChatGPTという現象について
GoogleがChatGPTのリリースを警戒して昨年末に非常事態宣言を出しました。今はMicrosoft+OpenAI対Googleの戦いが起きています。Microsoftの検索エンジンのBingにChatGPTが載ったことで、Bingユーザーが増え始めるという現象も起きています。Googleが慌ててBardという会話型AIサービスを出したのですが、拙速に出してしまって間違いがあり、Googleの株価が下がってしまいました。
ChatGPTなど大規模言語モデルによって社会は大きく変わると思います。わかりやすく示すと、「検索」がなくなる可能性が高いです。質問をして、このページを自分で読んでと返してくるのと、答えそのものを返してくるのと、どちらがよいかというと、答えを教えてくれる方がよいです。つまり、世界トップクラスの会社の主力事業がなくなるかもしれないということです。Microsoftからすると、Office製品が変わることが重要です。人間が自分で一字一句打つ時代は終わります。仕事の仕方が大幅に変わるでしょう。
目的に特化した学習をさせれば、専用のChatGPTが作れます。〇×をつけて報酬モデルを学習し、それを使って強化学習をするため、〇×の付け方によって全然違う対話型AIになります。データソースとしても一般的なウェブからとってきたものを使うのか、もっとドメインスペスフィックなものを使うかで変わってきます。例えば法律的な見地から正しいコメントをするChatGPTや、医学的な見地から正しいコメントをするChatGPTもできます。今のChatGPTは感情を動かさないようにできていますが、逆に感情を動かす、例えば相手を慰めたり励ましたりするようなものもできます。相手の理解に合わせて分かりやすく教えてくれるChatGPTもできます。
さらに、相手の要望を聞き出して目的の商品を勧める、複数の人の希望を聞いて妥協点を調整するようなものもできるでしょう。恐らくホワイトカラーの仕事のほぼ全てに何らかの影響があると思います。それが2、3年のうちに起きてくるということです。

▲ スライド14・ChatGPTによって社会はどう変わるか
ChatGPTに関連して日本がとるべき戦略は?
日本としては3つ戦略があります。1つめは、自ら大規模言語モデルを開発することです。2つめは、APIを使ってサービスを作ることを奨励することです。3つめはユーザーとして活用を促進することです。DXが進んでいない現状においては、言語による指示ができるのはすごく重要で、リープフロッグのように一気にDXが進む決め手になるかもしれません。いずれにしてもChatGPTは、2カ月の間に1億人が使ったということで、社会に変化が起きることが確定したと思っています。資金も人もどんどん流れ込んでいます。そういった未来が来ると人々が信じたからこそ、そういう未来が本当にやってくるのだと思います。

▲ スライド15・日本の戦略
最後に教育がどう変化するかについてですが、これは分かりません。でも敢えて予測すると、より個人化されたインタラクティブな教育ができるようになるでしょう。これまでもエドテックなどでそういったことは謳われていましたが、なかなかコンテンツの中身までは手を入れることができませんでした。それができるようになって、分かりやすく教えられるようになります。ユーザーの理解のモデルを使った評価もできるようになります。
次に、必要とされる能力も変化していくだろうと思います。記憶や単純作業はますます不要になるし、例えばコンサルタントファームのアシスタントのような役割はいらなくなるでしょう。多くの情報から必要なものを探して整理することも不要になります。プログラミングすら不要になる可能性もあります。そうはいっても、全体の理解や真の意味での創造性、リーダーシップは依然として重要であり続けるでしょう。
また、教育を考える際には5年10年20年のスケールで考えますが、その時間スケールと、3カ月前に出たChatGPTがこれだけ世間を席巻しているという技術の進化の速度が全く合っていない感じがあります。教育は時代を見通して先回りして活躍できる人を育てたいというのがあると思いますが、先回りするのは無理という感じを受けます。今よいと思っていることをやり続けるしかないと感じています。

▲ スライド16・AIによって教育はどう変化するか
>> 後半へ続く




