AIと教育の関係性を「3つの視点」で考える
第52回オンラインシンポレポート・前半
活動報告|レポート
概要
超教育協会は2021年6月30日、理化学研究所革新知能統合研究センター長、東京大学大学院新領域創成科学研究科教授の杉山 将氏を招いて、「AIの教育,AIによる教育,AIのための教育」と題したオンラインシンポジウムを開催した。
前半は、杉山氏が「人間がAI技術を学ぶ」、「AIが人間の学習を支援する」、「AIが学ぶことを人間が支援する」という3つの視点でAIと教育について説明し、後半は、超教育協会理事長の石戸 奈々子をファシリテーターに、参加者を交えての質疑応答が実施された。その前半の模様を紹介する。
>> 後半のレポートはこちら
>> シンポジウム動画も公開中!Youtube動画
「AIの教育,AIによる教育,AIのための教育」
■日時:2021年6月30日(水)12時~12時55分
■講演:杉山 将氏
理化学研究所革新知能統合研究センター長
東京大学大学院新領域創成科学研究科教授
■ファシリテーター:石戸 奈々子 超教育協会理事長
杉山氏は約30分間の講演で、理化学研究所革新知能統合研究センターの活動やAIと教育の関係性について説明した。
【杉山氏】
理化学研究所革新知能統合研究(AIP)センター(以下、AIPセンター)は、文部科学省が進める人工知能(AI)、ビッグデータ、IoT、サイバーセキュリティに関する革新的基盤技術の研究「Advanced Integrated Intelligence Platform Project(AIP)」の拠点として2016年に設立されました。東京大学や一般企業とも連携しながら、「5本柱」で研究を進めています。
1つめは、「次世代AI基盤技術の開発」です。おもに基礎理論の研究に取り組んでいます。2つめが、「AIを使った科学研究の加速」です。再生医療やガンなど病気の治療、材料など日本が強い研究分野も、今やAIなしでは研究が進まなくなっています。AIを活用し、これらの分野の研究を加速させる取り組みを進めています。3つめは、日本が抱える社会的課題、例えば高齢者のヘルスケア、防災減災などにAIを活用する取り組みです。4つめは、AIに関連した技術開発ではなく、AI活用における倫理的、法的な課題への対応についての研究です。倫理指針の策定、公平性・信頼性の規準策定などに取り組んでいます。5つめはAI人材の育成です。国内外問わず学生、研究員、エンジニアが一緒に活動しています。

▲ スライド1・理化学研究所AIPセンターの研究の5本柱
「人間がAI技術を学ぶ」「AIが人間の学習を支援する」という2つの視点
AIと教育について考えるときには、「人間がAI技術を学ぶ」という視点と、「AIが人間の学習を支援する」という2つの視点があります。
「人間がAI技術を学ぶ」、つまり「AIの教育」という視点では、今やAIを学べるスクールは数多くあります。東京大学も外部の組織でデータサイエンススクールを運営しています。AIに関する知識や技術を客観的に評価してもらう検定制度もあり、統計検定とディープラーニング検定が知られています。
政府のAIデータサイエンスの教育プログラムや認定制度の議論も始まり、「リテラシーレベル」、「応用基礎レベル」、「エキスパートレベル」と3つに分け、応用基礎レベル以上には認定制度も作られます。対象は高専卒業者以上とかなり幅広く考えられており、徐々にレベルを上げて年に100人ほどの「トップスター」を育てる環境が整備されます。
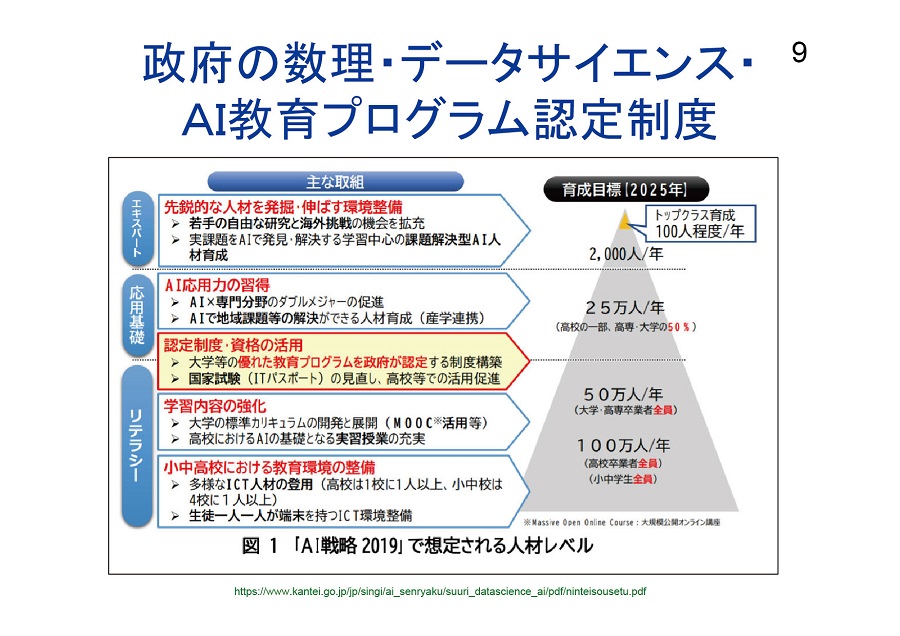
▲ スライド2・政府でもAI教育プログラムの
認定制度について議論が進められている
国内外で普及が進むAIを活用した学習プラットフォーム
利用者が増えると「探索と活用のトレードオフ」も
一方、「AIが人間の学習を支援する」、つまり「AIによる教育」という視点では、すでにAIを活用して学習をサポートする教育プラットフォームがいくつも登場しています。経済産業省のホームページでも「EdTech」として紹介されています。国際的には、「MOOCs(Massive Open Online Courses )」が広く知られています。その他にも機械学習の研究者のチームが作った「Coursera」は2021年3月にIPO(株式上場)し、時価総額が50億ドル(1ドル=110円として5500億円)にも達しました。
MOOCsは、オンラインで世界各国の有名大学の授業を受講できる教育プラットフォームです。さまざまなカリキュラムを無料で受講できますが、修了証明の取得は基本的に有料です。受講に関するさまざまなデータを収集・活用し、講義内容を改善したり、受講生に次のコースを推奨したりしているのが特長です。日本語字幕がついているカリキュラムもあります。東京大学も小規模ながらMOOCsで講義をしています。日本語のJMOOCというサイトもあるなど、世界的に公開講座を行う動きが加速しています。
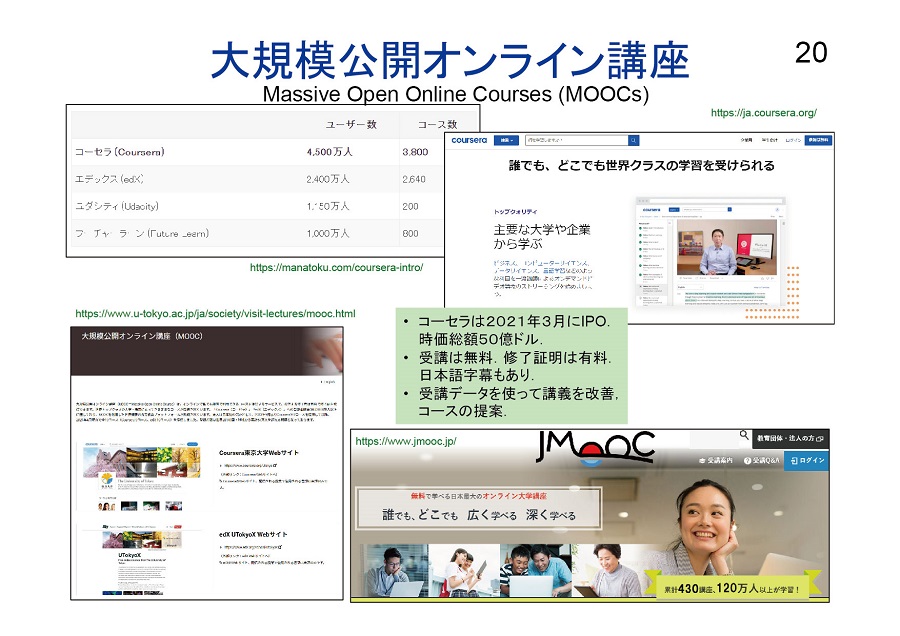
▲ スライド3・世界的に、無料で受講できる
オンライン講座が増えている
また、日本では、学習塾や予備校でAIを活用した学習支援や受験支援の取り組みが進められています。「最適な受験勉強をAIが教えます」と、AIを使ったシステムも実用化されていますが、じつは機械学習の研究の観点では難しい分野です。AIによる学習システムを作る過程では、さまざまな勉強法を試して成功や失敗を「教師データ」としてAIに機械学習させてシステムを作り込むことができます。さまざまなデータから最適な戦略、つまり学習方法などを導き出せるようになるのです。
しかし、ひとたびシステムができて、全員がシステムの指示通りに勉強すると、AIとしては機械学習するための教師データ、思考錯誤するデータが発生しなくなります。これは機械学習において非常に大きな問題で「探索と活用のトレードオフ」といわれています。活用段階に入ると、多様性が失われていってしまうのです。
現時点では、AIを活用した教育システムはまだ「実用化したばかり」の段階です。そのため、優れた点ばかりが注目される傾向にありますが、この先、5年、10年と同じシステムを同じように使い続けると、みんが同じように点数が上がり、「差がつかなくなる」ことも考えられます。受験のようなゼロサムゲームには、支障が出てくるのではないかと考えられます。

▲ スライド4・普及が進むAIを活用した
受験支援のシステムの機械学習には問題がある
そういった視点に立てば、今後、教育分野にAI活用では、受験生の希望する大学と大学側が求める学生とをマッチングする仕組みの構築などが考えられます。AIによる学習支援で単純にテストの点数を上げるのはなく、子供たちが「やりたいことを見つける」、自己実現のためにAIのシステムが活用されることも大切になってくるでしょう。
AIが文章の質を評価するシステムや膨大な論文から重要な情報を抽出する仕組みも研究中
AIによる学習の支援という視点で、理化学研究所AIPセンターでのAIに関する研究について説明します。例えば、「文章を上手に書く」と考えたとき、学ぶことも教えることも難しいでしょう。そこで、文章の質の評価をAIで自動化するシステムを研究中です。
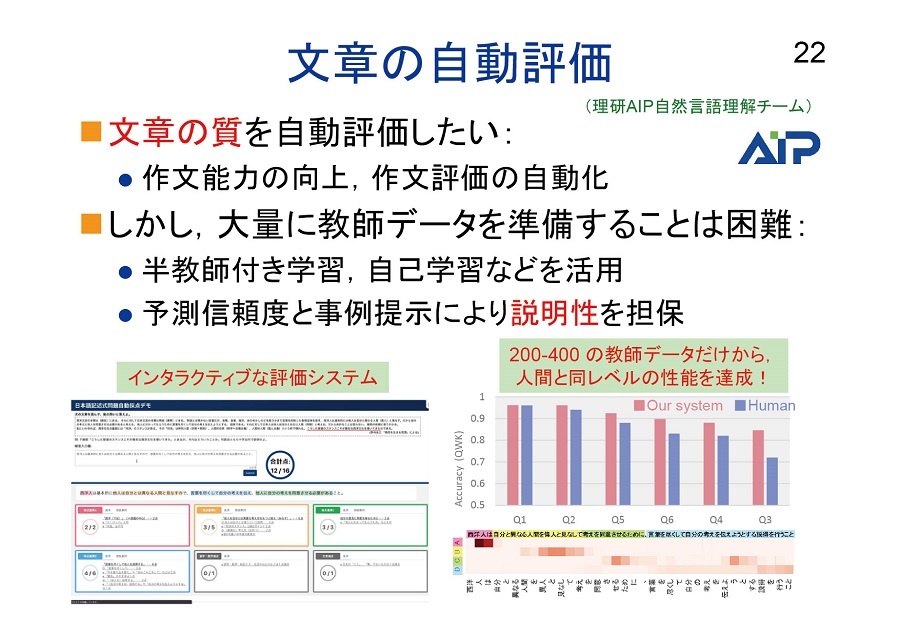
▲ スライド5・文章の質を自動的に
評価するシステムを開発・研究中
ただし、書いた文章が上手か下手かを先生に評価してもらうことは、とても手間がかかるため、データがあまり取れません。教師データを十分に取得することができないので、「半教師付き学習」や「自己学習」といった新しい技術に取り組んで精度を高めています。また「機械に評価されても納得いかない」という人が多いという問題ついては、点数の根拠を過去データから同時に示すことで、精度と説明性のバランスを取っています。
このシステムでは200~400の教師データを集めて学習させ、人間の先生と同じぐらいの評価ができる性能が出せています。
また、文献からの情報抽出についても研究しています。何かを勉強するために本や文献を読みますが、論文に関しては多すぎてほとんど読まれないのが実情です。「Semantic Scholar」というサイトに登録されている論文は2億本弱、またコロナ関係の論文を集めたサイトには、40万本も登録されています。機械学習の国際会議でも、年間1万5千本も論文が投稿されています。
新しい研究結果がたくさん出ているのに、読まれず活用されないことは、非常に大きな問題です。そこで、自動的に情報を抽出できるシステムが必要であると考え、自然言語処理技術を活用したシステムの実用化を進めています。この仕組みを活用すれば、例えば、材料合成プロセスの論文から自然言語処理で自動的に必要な情報を認識して取り出し、材料の作り方のフロー図を自動的に作成することなどができるようになります。論文のデータから自動的にデータベースを構築することも可能となり、人間が何千本もの論文を読む必要はなくなります。
論文に書かれている情報の検索についても、キーワードでの検索では適切な結果が表示されないことがあります。そこで、自然言語処理の技術で、意味合いや言葉の関係性をしっかりととらえ、効率よく情報検索できる、いわば「玄人向けのシステム」を作ろうとしています。

▲ スライド6・膨大な数の論文を自然言語処理技術で読み、
検索して必要な情報を自動抽出するシステムを開発中
「これはイヌ」ではなく「イヌか鳥」のような曖昧データも学習させる「弱教師付き学習」への取り組み
AIと教育について考えると、もう一つ、「AIが学ぶことを人間が支援する」、つまり「AIのための教育」という視点も大切です。
現在のAIは、学習用の教師データを充分に用意することで、音声の認識、画像の理解、言語の翻訳など、人間を超える能力を発揮できるようになります。しかし、教師データを用意するのが難しい分野もあります。例えば医用画像の診断の場合、医師が判断してなんらかの病気を「発症している、していない」という「答え」がついたデータを膨大に集めることは困難です。
データを数多く集める方法としては、クラウドソーシングを利用してさまざまな人に「答え」つけをしてもらう方法があり、副業サイトとして認知度も高まっています。「これはイヌ、これはネコ」というような画像認識のデータ作成などには有効ですが、プライバシー情報を含むデータは不特定多数の作業者に任せられない、また、専門的な判断が必要な場合には答えの信頼性をどう担保するかの問題があります。
他のデータ作成の方法としては、能動学習という概念があります。普段はランダムにたくさんデータを選びますが、そうではなく、重要そうなデータだけを選んで答えつけるという考え方です。この方法は、理論的にも実験的にも有効であることが分かっていますが、作業手順に問題があります。答えを付けたデータをシステムに学習させて、次の質問をする、というインタラクティブな作業を、システムに張り付いて行わなければなりません。
このように質のよいデータを集めることが困難であるため、別の発想で、質が悪くても低コストで膨大なデータを集められる方法を研究しています。
例えば、イヌとネコの区別では、データに他の動物も混じっていてもよく、「これはネコではない」という「真の答え」以外の答えのついたデータ、あるいは「イヌか鳥」のような曖昧な答えがついたデータでも集めてしまうという考えです。これらは、真の答えがついた普通のデータよりもはるかに簡単に、たくさん集められます。そして間違った答えや曖昧な答えの情報からだけでも、システムはしっかり学習できます。
この研究は「弱教師付き学習」で、もう少しで一般化できますが、この技術が普及すると、コストをかけずに、簡単に集められるデータだけを使って機械学習を実現できるようになります。

▲ スライド7・真の情報ではない「間違った」データや
「曖昧な」データなら簡単に集められることに着目した学習方法
現在のAIには「だまされやすい」性質も「信頼性」の研究が重要に
人工知能は1960年頃、記号処理や論理推論を使って知能を作る研究が第一次ブームとなりました。論理的人工知能の研究は日本で盛んに行われて、1980年代の第二次ブームではエキスパートシステムが作られました。
それと並行して脳型情報処理システムを作ろうとブームになりました。脳の神経細胞を簡略したパーセプトロンというモデルを使うもの、1980年頃には多層型でもうまく学習できるという誤差逆伝播法が作られました。この当時は「ニューロ」や「ファジー」がトレンドとなり洗濯機やエアコン等にも盛んに使われました。
2000年頃になると統計的機械学習が大きなブームになりました。統計・凸最適化、カーネル法、ベイズ推論の研究が発展し、いろんな企業で実用化されていきました。
その後、脳型情報処理と統計的機械学習が組み合わせられ、昨今の深層学習の大きなブームが来ています。今後に向けては、第一次ブームの論理的人工知能と、最先端の深層学習の技術を組み合わせると人間らしい知能を作れるのではないかと、研究が進められています。
ただし、ここで考えておきたいのは、本当に、「人間のようなAI」を作りたいのでしょうかということです。未来のAIは人間のようになって自立して学習していく必要はなく、人間のパートナーとして一緒に学習していくものでもよいのではないでしょうか。
▲ スライド8・AIは人間のようにならなくてもよいのではないか、
共に学習していければよい
ファッションデザイナーの方と仕事をさせていただく機会があった際、AIを使ってデザインのアイディアを出し、デザイナーの方に見ていただいてフィードバックをいただき、それをAIが再び学習して…と繰り返していくと、人間のデザイナーが新しいアイディアを得て、よりクリエイティブになるという経験をしました。共に学ぶことが重要なのだと思います。
最終的にAIは「人間社会で活用されるもの」です。性能の高さを数字で追求するだけではなく、人間の知識、創造性、文化、倫理を融合して人間にとって自然な予測をしてくれるもの、パートナーとしてふさわしい動きをしてくれるものを作って行く必要があると思います。
将来パートナーとなるには「信頼性」が重要ですが、今のディープラーニングには「だまされすい」性質があります。例えば、きちんとディープラーニングすると正しく「パンダ」と認識される画像に、わずかな雑音を乗せると、人間の目には全く同じパンダに見えるのに「gibbon (ギボン=テナガザル)」と認識されてしまい、しかも「99%以上の信頼性」と出てしまうことがあるのです。
似た事例で、自動運転者が「止まれ」の看板の認識を学習するときに、「止まれ」の看板に何かシールをひとつ貼ると、それが「速度制限100km」の看板に見えてしまう、という話もあります。いたずらができてしまうことは大きな問題です。パートナーになるためには信頼性に関する基礎研究をしっかり行っていくことが重要な課題です。
今後は「AIと共に学ぶ」ところを深めていく必要があると考えています。性能を上げることと、社会から必要とされているものを見極め、両方を満たすよいものを作っていきたいと思います。
>> 後半へ続く